원문: https://blog.avenuecode.com/callback-hell-promises-and-async/await
Callbacks와 promises, 그리고 async/await을 쓰는 비동기 자바스크립트는 반환하는데 시간이 소요되는 함수에 도움이 된다. 이 글은 기본적으로 callbacks, promises, 그리고 async/await이 어떻게 작동하는지 그리고 읽을 수 없는 복잡한 callback을 이해하는데 도움을 줄 것이다.
Callbacks
Callback 함수는 주로 다른 함수의 매개변수로 사용된다. Callback 함수를 매개변수로 받는 함수는 보통 데이터베이스로부터 데이터를 받거나, 파일을 받거나, API 요청을 하거나, 작업 완료가 코드 Thread를 오랜 시간 Block할 수 있는 코드이다.
가령, 이미지를 받는다고 해보자. 이미지를 받는데 2초가 걸리는데, 다운로드가 진행되는 동안 코드 실행이 안 멈추길 원한다. Callback은 다른 함수들이 작동하면서 이미지 다운로드가 완료됐을 때 "알려 준다."
setTimeout 함수를 통해 이미지를 다운로드하는 상황을 가정해보자. (우측은 작동 로그이다.)
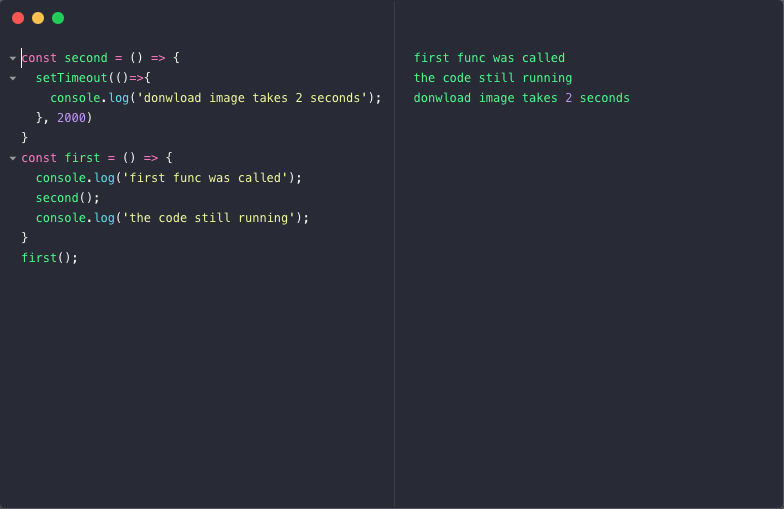
보는 바와 같이, setTimeout 함수가 있는 callback 함수에 의해 second() 함수는 2초 후에 작동한다. 다운로드가 진행되는 동안 first() 함수는 끊김없이 실행됐다.
다시말해, callback 함수는:
- 함수가 "Background"에서 실행될 수 있도록 하고,
- 함수의 실행이 완료되면 실행이 되며,
- 코드의 실행을 막지 않는다. (Non-blocking)
그러나, 엄청난 힘에는 엄청난 무책임이 따른다 :). 비동기 호출을 하는 몇몇 함수들은 다음과 같이 좋지않게 짜여질 수 있다.
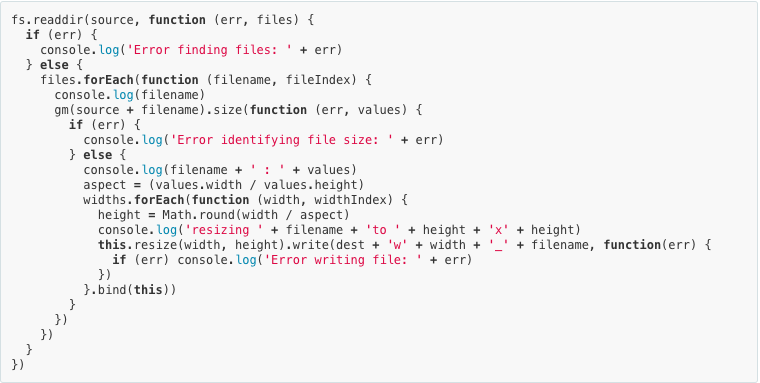 |
| Callback 지옥 |
위의 코드는 이해하기도 어렵고, 관리하기도 어려우며 확장성도 낮다. 이걸 우리는 Callback 지옥이라 부른다. (심지어 이에 대한 자세한 설명이 있는 callbackhell라는 사이트도 있다.)
최신 Javascript에서는 이 고통을 끝내 줄 두개의 약속이 있다. 이들은 바로 promises와 async/await이다.
Promises
Promises는 차후에 사용이 가능할 무엇인가를 표현하는 Object이다. 프로그래밍에서 무엇이라고 하면 값을 의미한다. Promises는 원하는 값을 기다리는 것이 아닌, 받을 값을 표현하는 것을 즉시 받아 "해야할 일을 먼저 하고" 때가 되면 다시 돌아가서 promise에 의해 생성된 값을 사용하는 방식을 제안한다.
Promises는 시간 사건에 기반하며 이를 구분하는 몇몇개의 상태가 있다:
- Pending (대기중): 이벤트가 발생하기 직전
- Settled/Resolved (~진행중): 이벤트가 시작한 시점
- Fulfilled (~성공): 정상적으로 promise가 값을 반환한 경우
- Rejected (~실패): promise가 비정상적인 값을 반환한 경우
Promise를 생성했을 때, 새로운 promise를 생성하고 결과를 반환하는데 해당 promise를 사용한다. Promise를 사용할때는, 상태가 Fulfilled인지 Rejected인가에 따라 Callback 함수를 사용한다.
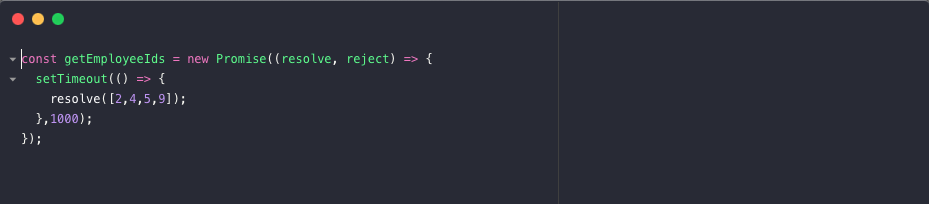
해당 예시에서, 직원들의 ID들을 찾는 promise를 생성하였다. promise Object는 두개의 callback 함수, resolve와 reject 함수를 받는다. 이 callback은 executor function이라 부르며, promise가 생성될 때 호출된다.
executor function는 이벤트가 성공했는지의 promise를 알려준다. 성공했다면 resolve가 호출이 되고, 실패했다면 reject 함수가 호출된다.
promise를 사용해보자. 이를 위해 then()과 catch() 두개의 함수를 사용할 것이다. 모든 promise는 이 두개의 함수를 상속받는다.
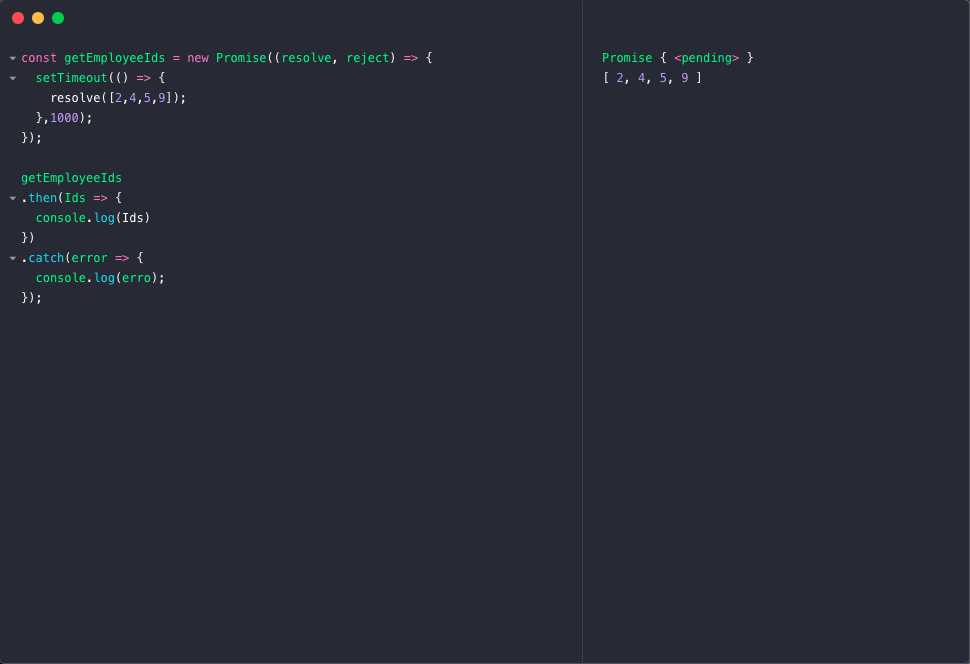
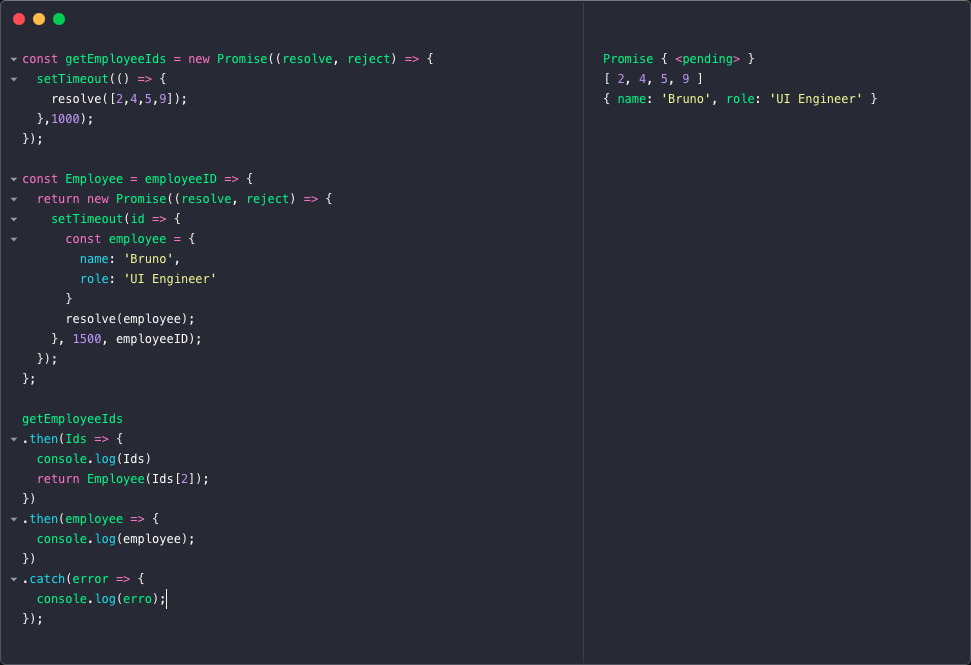
반환된 데이터를 처리하는 callback 함수를 주어야 한다. 이 callback 함수는 매개변수를 받는데--이 예시에서는 ID들이 된다. ID들 매개변수는 promise의 결과이며, 반환 결과는 callback 함수가 지정한 배열을 받게 된다.
catch 함수는 유사한 방식으로 작동하나, reject 함수를 위한 결과를 반환한다.
Callback 지옥을 해결하기 위한 promise의 기본 원리들은
- 모든 promise는 callback들의 결과에 대한 제어권을 갖는다: resolve, reject 함수
- 모든 promise Object들은 then(), catch() 함수를 가지고 있다.
하지만 마술사에게 마법이 돌아오지 않도록 조심해야하는데, promise callback 지옥이 생길 수 있다. user를 인증한다고 상상해보자. (단지 예시로써)
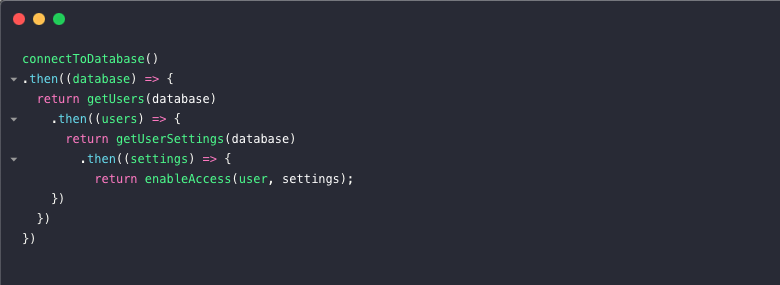
이 promise 사용에서 Callback 지옥의 패턴을 알아볼 수 있나? 하나의 호출에 다른 호출 그리고 더 많은 호출이 붙기 시작하면 이 코드는 가독성이 떨어지고 관리하기 어려워진다.
그래서 언제나 좋은 promise 구현들을 기억하고 있어야한다. 예를 들어, 몇몇 상황에서 모든 promise들을 한번에 해결할 수 있다:

하지만 Promise.all()을 사용하는 건 promise의 순서에 상관이 없을때 사용한다. promise의 순서를 다음과 같이 지정해줄 수 있다:

이 짧은 표기법은 then() 함수가 promise를 반환하기 때문에 작동한다. 여기에 따르기 좋은 관습에 대한 글이 있다.
Async/await
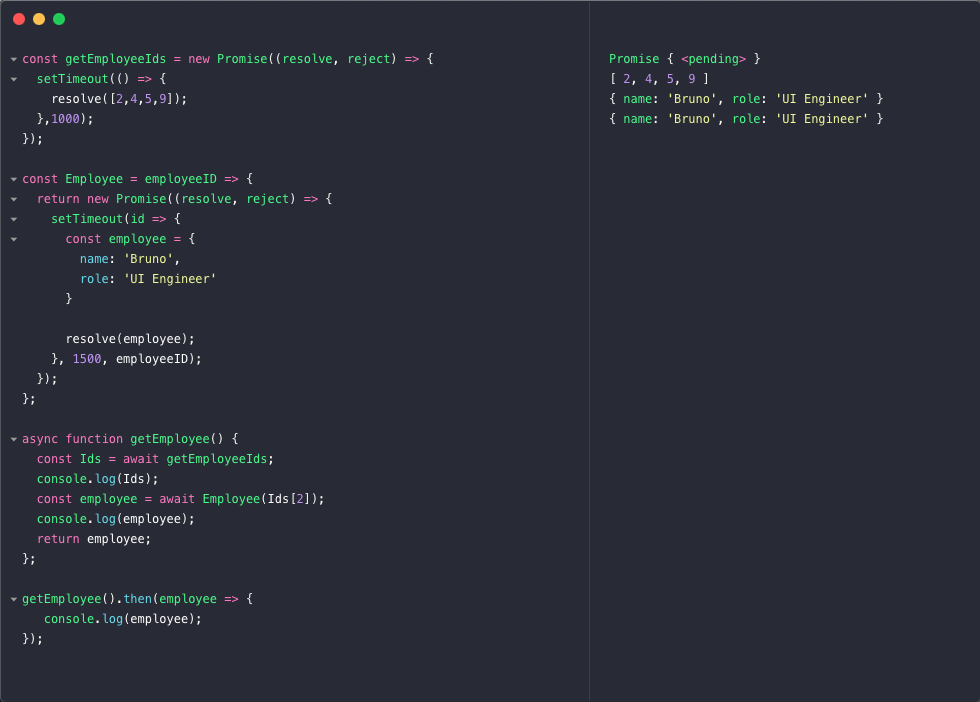
Async/await은 promise를 사용할 수 있는 대안으로, ES8이나 ES2017에 구현돼 있다.
이 코드에서 다음과 같은 일이 일어나고 있다: async 함수를 async 키워드를 function 키워드 앞에 작성함으로 생성한다. 이 함수가 비동기, background에서 작동한다는 것이다.
그래서 async 함수에서는 무슨 일이 생기는가?
async 함수는 하나 또는 여러개의 await 표기들이 들어가며, promises들을 await이라는 표기를, promise의 resolved 함수의 결과를 반환하는, 통해 사용했다.
이는 간단히 말해 비동기 경우들을 background에서 Top-Down 방식으로 처리한다는 것이다.
기억해야 할 중요한 부분은, async 함수는 promise를 반환한다는 것이다. 그래서 getEmployee() 함수를 반환하므로 then() 함수를 사용해야 하고 그렇게 하여 예상한 결과를 반환한다.--그래서 promise의 개념과 어떻게 작동하는지를 잘 알아야 한다.
callback들과 promise들 그리고 async/await을 위한 튜토리얼은 이정도다. Let me know how it goes for you!